Why Aren’t We Talking About Experiment Management as Much as We Should Be?
The reproducibility crisis in machine learning is real—here’s what we can do about it
If you’re anything like me, you’ve been sucked into a black hole for days or weeks on end experimenting with various techniques to find the best fit machine learning model for the task at hand.
You could be working on an NLP project, coming up with a baseline algorithm, playing with Naive Bayes, changing it up to random forest, or remembering that time your mentor put you onto RNNs because they read a paper that showed this architecture performs really well on this kind of text data.
We spend a lot of time thinking about these kinds of problems. But how much time do we spend thinking about how to manage our machine learning experiments?
Or how we track, score, and evaluate our models?
Or about how we can ensure reproducibility?
How are we taking into account the various other things we try like n-grams of all sizes, TF-IDF, removal of stop words, special characters, all the hyper parameters we end up tuning downstream, and all the other things we’re scribbling in our Moleskine?
Why Do We Need Experiment Management?
Because if anything is true about the machine learning process, is that it abides by the CACE Principle.
The CACE Principle
Changing Anything Changes Everything
The phenomena by which change anywhere in the machine learning process — especially those furthest upstream — will have unanticipated impact on your experiment and results.
This is why we need experiment management.
Experiment management helps us build better models faster because it allows us to track our progress as we iterate through various combinations of features, algorithms, data processing techniques, hyper-parameters, etc.
It provides us a way to manage those iterations, glean insights into the progress we’re making on our projects, and keeps our projects from spiralling out of control.
It allows us to seamlessly manage the logistics of machine learning so that we can focus on the scientific process of experimentation.
And if we can manage this with minimal effort on our end, we can focus on chasing that gratifying sense of competence when you find the best fit model and deploy it into production.
How Should We Be Managing Our Experiments?
Experiment management is something we know we should be doing!
However most data scientists I’ve spoken to…don’t.
And if they are managing their experiments, it’s an ad hoc process at best. A process that typically involves some type of source control — like GitLab.
“What?!
What’s wrong with Git?
Can’t I just use Git for all of this?
Is Git not enough?”
Look, Git it awesome. It will for sure save all your code.
But sometimes the code itself isn’t enough…so what do we do?
Git. Commit. Everything.
At best, we might tag a branch to, say, leave a commit message that says something cryptic like “This branch worked” or “Final Final v2.2, 3-gram, TF-IDF, HuggingFace.”
This isn’t what Git was built for, though.
Git can’t save your trained models, much less all the useful metadata from your runs: the various metrics, model parameters, upstream dependencies, distribution of features within the dataset, data scaling and splitting techniques, type of optimizer being used, etc., etc., etc., etc., etc.
Sure you’ve got the code, but you’d only have access to the information you care most about if you ran the code from start to finish.
That could take hours, days, or weeks, which of course you wouldn’t know unless you ran the code and found out the hard way.
If you’re a little more disciplined, you might use a spreadsheet to track everything, like this one (which honestly, isn’t that impressive or sophisticated):
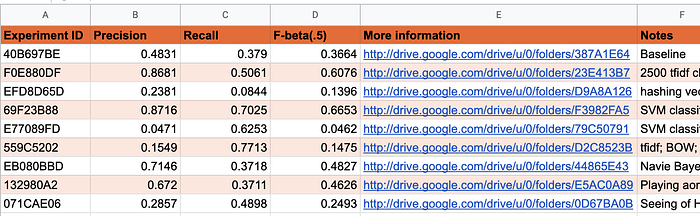
This is the sad state of how most aspiring, early career, and solo data scientists are managing most of their machine learning code.
We don’t have to work like that.
Tuning and serving your models paves the way for faster model iteration and smoother deployment. Learn more in our experiment management webinar series.
Experiment Management Helps You Manage the Nagging Logistics Inherent in the Iterative Nature of Machine Learning Development
“Harpreet…Look man, that’s all fine. But I got science to do, homie.”
I get it, you don’t want to hear all this.
As scientists, we want to focus on the science!
Not the engineering.
Or the reproducibility.
Or environment variables.
Or configuration files.
Or all the other artifacts and stuff that’s kept track of.
Keeping track of and managing all this extraneous metadata stuff is just too tedious, it creates more overhead, and you seriously run the risk of cognitive overload.
You probably feel like you don’t need many of these bits and pieces of information…until you do.
Because the time will come when you go back to that experiment after a week, or a month, or a year, or you want to bring on collaborators, or share your work with somebody else.
And when that happens, how is that person (future you, or present day collaborator) supposed figure out the end-to-end process of how the experiment was run?
I don’t have all the answers for you, but I think it’s important that we start having this conversation.
As mentioned in this informative blog post, a recent survey of researchers showed that more than half have admitted to failing to reproduce the result of another scientist’s experiment.
Unless we take responsibility for our experiments and manage them effectively and consistently, the reproducibility crisis will be a blight on our blossoming field.
When we execute our model building processes and analyses with rigor, consistency, transparency, and traceability, we’ll find that our research is more fleshed out, easier to understand, and there is a clear lineage— which takes us from data to decisions.
Here are some things you can do, starting today, to set yourself on the path toward better-managed experiments and more reproducible work:
- Version control your code in a central repository, like GitLab.
- Version control your datasets, pre-trained models, and other artifacts used in the model development process.
- Track your experimental runs using an open source tool like MLFlow.
- Get more sophisticated and track metadata like hyper parameters, random seeds, CPU/GPU usage, environment configuration, source code, system metrics, command line arguments, plus results from experimental runs using the free tier of a managed platform like Comet.
- Stay ahead of issues in production using a tool that enables you to gain visibility into your model performance in real time.
If you’re wondering where to even start with standardizing your experimental process, then be sure to check out this free e-book from Comet.
How are you managing your experiments? How has your experiment management process changed from when you first started in machine learning? Is this your first time thinking about experiment management?
Let me know your thoughts in the comments.
Also be sure to check out our full Office Hours sessions on YouTube!
And remember my friends: You’ve got one life on this planet, why not try to do something big?
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Comet Newsletter), join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.

